
EgoGen: a scalable synthetic data generation system for egocentric perception tasks, with rich multi-modal data and accurate annotations. We simulate camera rigs for head-mounted devices (HMDs) and render from the perspective of the camera wearer with various sensors. Top to bottom: middle and right camera sensors in the rig. Left to right: photo-realistic RGB image, RGB with simulated motion blur, depth map, surface normal, segmentation mask, and world position for fisheye cameras widely used in HMDs.
Abstract
Understanding the world in first-person view is fundamental in Augmented Reality (AR). This immersive perspective brings dramatic visual changes and unique challenges compared to third-person views. Synthetic data has empowered third-person-view vision models, but its application to embodied egocentric perception tasks remains largely unexplored. A critical challenge lies in simulating natural human movements and behaviors that effectively steer the embodied cameras to capture a faithful egocentric representation of the 3D world. To address this challenge, we introduce EgoGen, a new synthetic data generator that can produce accurate and rich ground-truth training data for egocentric perception tasks. At the heart of EgoGen is a novel human motion synthesis model that directly leverages egocentric visual inputs of a virtual human to sense the 3D environment. Combined with collision-avoiding motion primitives and a two-stage reinforcement learning approach, our motion synthesis model offers a closed-loop solution where the embodied perception and movement of the virtual human are seamlessly coupled. Compared to previous works, our model eliminates the need for a pre-defined global path, and is directly applicable to dynamic environments. Combined with our easy-to-use and scalable data generation pipeline, we demonstrate EgoGen’s efficacy in three tasks: mapping and localization for head-mounted cameras, egocentric camera tracking, and human mesh recovery from egocentric views. EgoGen will be fully open-sourced, offering a practical solution for creating realistic egocentric training data and aiming to serve as a useful tool for egocentric computer vision research.
Abstract
Understanding the world in first-person view is fundamental in Augmented Reality (AR). This immersive perspective brings dramatic visual changes and unique challenges compared to third-person views. Synthetic data has empowered third-person-view vision models, but its application to embodied egocentric perception tasks remains largely unexplored. A critical challenge lies in simulating natural human movements and behaviors that effectively steer the embodied cameras to capture a faithful egocentric representation of the 3D world. To address this challenge, we introduce EgoGen, a new synthetic data generator that can produce accurate and rich ground-truth training data for egocentric perception tasks. At the heart of EgoGen is a novel human motion synthesis model that directly leverages egocentric visual inputs of a virtual human to sense the 3D environment. Combined with collision-avoiding motion primitives and a two-stage reinforcement learning approach, our motion synthesis model offers a closed-loop solution where the embodied perception and movement of the virtual human are seamlessly coupled. Compared to previous works, our model eliminates the need for a pre-defined global path, and is directly applicable to dynamic environments. Combined with our easy-to-use and scalable data generation pipeline, we demonstrate EgoGen’s efficacy in three tasks: mapping and localization for head-mounted cameras, egocentric camera tracking, and human mesh recovery from egocentric views. EgoGen will be fully open-sourced, offering a practical solution for creating realistic egocentric training data and aiming to serve as a useful tool for egocentric computer vision research.
Egocentric perception-driven motion synthesis
Training in static scenes
As William Gibson stated: We see in order to move; we move in order to see.
We close the loop for the interdependence between egocentric synthetic image data and human motion synthesis.
Our autonomous virtual humans are able to see their environment with egocentric visual inputs, explore by themselves, without being constrained by predefined paths.
The policy network learns a generalizable mapping from motion seed body markers \( \mathbf{X}_t^S \), marker directions \( \mathbf{X}_t^{S^D} \), egocentric sensing \( \mathcal{E}_t \), and distance to the target \( d_t \) to CAMPs. The policy learns a stochastic collision avoiding action space to predict future body markers \( \mathbf{X}_t^F \). For illustration purposes, we visualize only one frame of \( \mathbf{X}_t^S \) and \( \mathcal{E}_t \).
Generalization to dynamic settings
While the model is trained in static scenes, it demonstrates direct generalizability to dynamic settings, including dynamic obstacle avoidance and crowd motion synthesis.
Moving Obstacle
Two People
More People
Even More People
Besides, our generative human motion model allows for generating diverse crowd motions for diverse body shapes, incorporating variations in height and weight.
PhysicsVAE [Won et al. 2022]
Ours
Static body shapes in the left video

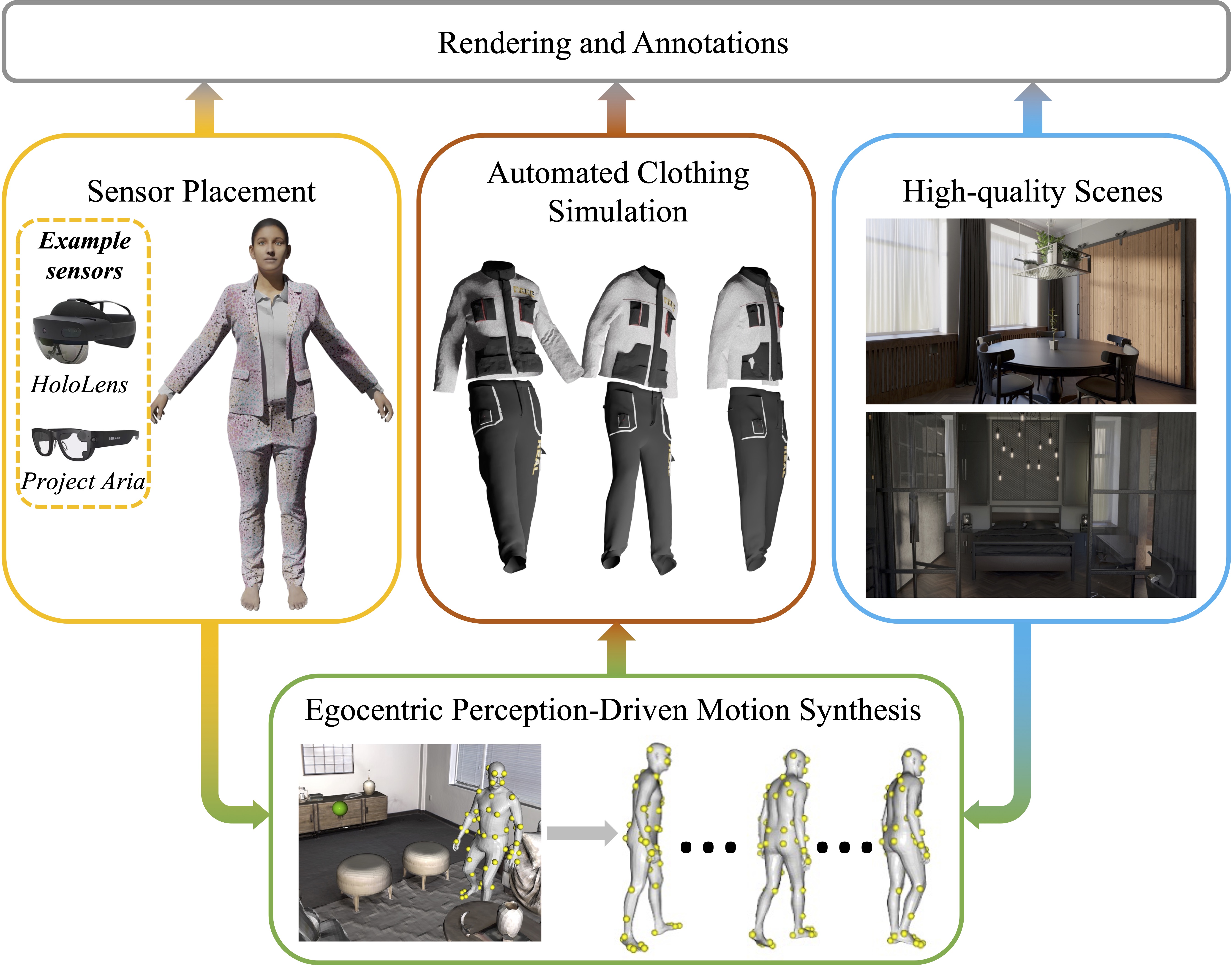
Overview of EgoGen
Through generative motion synthesis (green), we further enhance egocentric data diversity by randomly sampling diverse body textures (ethnicity, gender) and 3D textured clothing through an automated clothing simulation pipeline (red). With high-quality scenes and different egocentric cameras including multi-camera rigs (orange), we can render photorealistic egocentric synthetic data with rich and accurate ground truth annotations.
Applications
Mapping and Localization for HMDs
EgoGen has the capability to produce realistic synthetic egocentric data that closely matches real-world captures. We visualize some synthetic images and their extracted feature points with SuperPoint:



Red denotes detected 2D feature points and magenta denotes triangulated 3D points.
And we show some render-to-real image pairs matched with SuperGlue:


EgoGen can let virtual humans explore large-scale scenes, render dense egocentric views, and build a more complete SfM map, and it holds promise for creating AR mapping and localization datasets for digital twin scenes without manual data collection, providing enhanced privacy preservation.
Human Mesh Recovery from Egocentric Views
We simulate the data collection process of Egobody and let two virtual humans walk in the scanned scene meshes from Egobody. We randomly sample gender, body shape , and initial body pose and synthesize human motions with our proposed generative human motion model to increase data diversity. For RGB data generation, to further increase data diversity and close the sim-real gap, we randomly sample body texture and 3D textured clothing meshes from BEDLAM and perform automated clothing simulation. The model exhibits notable improvement with large-scale egocentric synthetic data.
HMR from Depth
Synthetic data samples

Row 1: Synthetic depth images for HMR. Row 2: Images with simulated sensor noise.
Qualitative results
HMR from RGB
Synthetic data samples

Row 1: Synthetic RGB images for HMR. Row 2: Images with simulated motion blur.
Qualitative results
Qualitative results
HMR from RGB
Synthetic data samples